Introduction
Plenty has been said about smart pointers, but new developers still get confused as they approach the language. Even if there was no confusion, this blog’s premise is to learn first, then bother how often the topic has been discussed before.
I wish to say that it does not matter whether you are an experienced C++ developer, a novice, or a complete outsider; you might find something new. But if you know how smart pointers work and why we use them, this paper might not be for you, although I hope to surprise you!
Prerequisites
Smart pointers are an idea found in multiple languages, but we will talk about them strictly in terms of C++, so you must have some basic programming abilities and be able to read basic code in C++. (here is a quick tutorial that should be more than enough) and basic knowledge about Object Oriented Programming is required.
A general understanding of how computer’s memory works would be great, but I will try to explain everything as we go through it. If you ever get lost, need an explanation, or are just extra curious, I invite you to read this.
Table of contents
Open Table of contents
About variables. In general.
This might be a little too low of a starting point because anybody who knows the words smart pointers also knows what a variable is, but humour me for a second. Let us build a solid foundation on which we can go up.
The Cambridge Dictionary gives the following definition of the noun variable:
a number, amount, or situation that can change
- The variables in the equation are X, Y, and Z.
- The data was analysed according to neighbourhoods, but other key variables like credit rating and marital status were ignored altogether.That’s good but too grounded. Let us make it more general:
Something of a known type that has a value that can change.This definition, I think, correctly reflects the idea behind variables in mathematics and programming. We use variables as boxes that have a value and a type. We can read from and write into these boxes. But they are not abstract-magical instances; they exist inside computer memory registers.
In C++ we define variables like so:
int a{5}; // declare a variable 'a' of type int and initialize it with value 5
int b = 21; // declare a variable 'b' of type int and initialize it with value 21
int c; // declare a variable `c` of type intFrom a high-level point of view, what these three lines of code do is relatively simple. They declare three variables of type int, called a', bandc. Now, a’ and b have an initial value assigned to them, but c has none. In truth, the value of c is defined by the current state of the computer’s memory. We can use these variables in a program. Here’s a short example:
#include <iostream> //include header file that defines std::cout
int main() {
int a{5};
int b = 21;
int c;
c = a + b;
std::cout << a << " + " << b << " = " << c; // print text to the screen
}This compiles and, when run, prints a statement: 5 + 21 = 26, which is correct. So far, we have established that variables can be declared, read and written to, but where are they stored?
Heap and Stack
Whenever we run a program, sometimes called a process, the OS (Operating System) reserves a certain amount of memory for it. The exact amount of memory depends on the OS, but assume that we get 2 GiB of memory.
How does it do that? The OS governs memory, or, to be precise, memory addresses. It allocates a range of memory addresses for a process and does not give them to any other program until the requesting process has terminated.
Although it is a continuous block of memory, we treat it as five separate entities. The first three are not the topic of our research, but I will name them: text segment, initialized data segment, and uninitialized data segment. The other two, and our main topics, are called heap and stack. Both can hold variables, but there are significant differences between them.
Stack
The stack is a part of the memory allocated by the OS for our process. Here, C++ manages the memory automatically and is used by default. Memory stack does work like a stack data structure. We can put, read, or take out items only from the top. All variables are allocated whenever we enter a new scope; whenever we leave a scope, they are deleted. In addition to local variables, global variables and function arguments are also located on the stack.
As the language manages the stack automatically, it must know all variables’ types and sizes at compile time. Knowing a variable’s size at compile time can be a significant problem if you want to work with arrays and do not know what size they should be.
The stack is a relatively small address space but is efficiently used. The ‘juggling’ of variables also means it does not suffer from any memory fragmentation, which can be a problem with the heap.
Here is an example of some variables allocated on the stack:
const float PI = 3.14f;
int foo(float a) {
return a + 2;
}
int main() {
float bar = foo(PI);
int c = 5;
}Heap - a closer look
Heap is a different memory space where we can store our data. In C++ it is called a dynamic memory. The heap is much bigger than the stack, but there is a catch: we have to manage it ourselves.
What I mean by that is that we have to ask the operating system to allocate the memory for a variable and then let the OS know that we are no longer using it, thus freeing the memory.
But why would anyone use the heap if we have to do all of this additional work? There are three main reasons:
- Size - sometimes, we have variables bigger than the whole stack, or we might not know its size.
- Dynamics - because we manage the memory at run time, we can create data structures that grow or shrink.
- Lifetime - stack variables are bound with their lifetime to the scope that defined them. Heap, on the other hand, allows us to surpass the scope in which the variable was created.
We create a dynamic variable via the new keyword, like so:
int* dynamic_int = new int(5);In this example, I have created a dynamically allocated int. But wait! The type is not int; it is int*. Why is that? The operating system returns a memory address to the allocated variable, and the int* represents just that. It is called a pointer. We will talk about them more in the next section.
When we are done with our newly created variable, we should return it to the OS. That is even simpler; we have to delete the variable:
int* dynamic_int = new int(5);
delete dynamic_int;If we were to create a dynamic array, there would be a slight syntax difference.
int* dynamic_array = new int[10];Here, we create an array of ints with size 10. What is great here is that the size of the array does not have to be known at the compile time; it can even be a variable.
But when we want to free the memory allocated by an array, we have to use a slightly different keyword:
int* dynamic_array = new int[10];
delete[] dynamic_array;A typical example of using a dynamic memory is reading a text file. Let’s get even better, and let’s say that the text is a shader code (you can check an example in OpenGL here)
What we need to do is simple:
- open the file,
- read all of the text inside,
- close the file
- send the data to the GPU
- free the memory allocated for the text
We could read the text to a stack-allocated array, but we have no clue how big this file is. We could guess and make an array so big that no one would ever fill it, but that would exceed the size of the stack itself. And then probably someone would write an even bigger shader. Dynamic allocation allows us to allocate just enough memory for the shader.
Pointers - a closer look
What exactly is a pointer, and how do we define it? Conceptually, a pointer is a variable that holds a memory address to a resource, also called a reference. When we define a pointer like this:
int* referenced_int;We create a variable of type int* that points to an integer. Practically, pointers hold a register address where our resource is stored, which, in this case, is an int. They can be created for all variables, regardless of where they were allocated.
If a pointer holds only an address, why must we give it a type? The compiler and our program at runtime need to know the type of resource being allocated/deallocated and read/written to.
Remember that memory is just a series of registers we can fill in. Most of the registers in a PC are of the same fixed size, which on a 64-bit architecture is 8-byte. This means that whenever we want to have a variable bigger than a single register, we have to use multiple of them. Consider also a situation when we want to use a smaller variable, for example, int, typically 4 bytes, or achar, which usually takes 1 byte. Without knowing the variable’s type, we would wrongly interpret all pointers as 8-byte variables.
We use the dereferencing operator when we want to access the variable behind the pointer. We dereference a pointer by placing a * symbol before it, thus accessing its value.
#include <iostream>
int main() {
int* referenced_int = new int(5);
std::cout << referenced_int << std::endl; // here we print the pointer's value
std::cout << *referenced_int << std::endl; // here we print integers value
return 0;
}So, in line 4, we declare and define a new variable of type int* called referenced_int. We use the new keyword to allocate the memory and initialize it with a starting value of 5.
Line 6 prints the value of the referenced_int. As the pointer holds the memory address, printing it returned me a value of 0x609d156f72b0.
Line 7: we print the dereferenced pointer, thus accessing its value, and we get the number 5 printed to the console. After that, the program finishes.
The difference between a reference and a heap-allocated variable is worth mentioning. In C++, there exists an address-of & (ampersand) operator, also known as a reference; its function is well described by its name: it returns the memory address of a variable.
Does this sound familiar? It should. The address-of-operator creates a pointer to a variable, no matter where it was allocated.
#include <iostream>
int main() {
int n = 1;
int* ptr_n = &n; // pointer
std::cout << &n << "==" << ptr_n << std::endl;
}In line 4, we define an int variable called n. In the following line, we declare an int* pointer called ptr_n and initialize with the address to n. Line 7 prints a comparison between the address of n and the value of ptr_n, the address it points to. The results I got are:
0x7fffbbe1e5ac==0x7fffbbe1e5acThe result confirms that the pointer is a reference to that variable.
Now that we have covered all the basic properties of pointers, we should discuss why using them might be a bad idea.
Pointers - what can go wrong (will go wrong)
“Raw pointers are powerful tools, to be sure, but decades of experience have demonstrated that with only the slightest lapse in concentration or discipline, these tools can turn on their ostensible masters” ~ Scott Meyers in Effective Modern C++
As they say, with great power comes great responsibility. Memory is a finite resource, and although it is not as scarce as it used to be, we still have to be careful how we manage it. If we behave like unschooled children, things get messy.
Let’s see how exactly we can shoot ourselves with pointers! Don’t try this at work!
Null pointers and Dangling pointers
In many languages, there is this concept of a null, a value that can be assigned to a pointer, representing pointing at nothing. It is an equivalent of 0 in numbers. C language has NULL, but C++ offers us an upgraded version, a nullptr. In the end, they both serve the same purpose.
If we have a pointer that is set to null, like int* n = nullptr;, and we try to dereference it, guess what happens?
#include <iostream>
int main() {
int* n = nullptr;
std::cout << *n << std::endl;
}We get what is called undefined behaviour, which can mean a lot of things, but the honest answer is that we don’t know. The program could crash, which is what happened in this case, but we could get something else. It’s an interesting form of Russian Roulette.
An interesting and somewhat dangerous quality of C++ is that the delete keyword does not set the value of a deleted pointer to nullptr. Deleting a pointer returns the memory to the operating system, which can do whatever it wants with that memory address. Consider the example below.
#include <iostream>
int main() {
int* n = new int(5);
delete n;
// From this point n is a dangling pointer
std::cout << *n << std::endl;
}Accessing a dangling pointer results in an undefined behaviour, as we, as programmers, have given up on managing that memory. Let’s see what happens if I run this on my machine:
-890627139This did not crash, but the answer I got was not correct. It is pseudorandom, determined by whatever the OS has put there. Because of that, I consider dangling pointers more insidious than a null pointer. A null pointer results in a crash, but this could be hiding somewhere inside your code base, and you wouldn’t even know about it!
Memory leak
A memory leak is when the program allocates some memory and loses a reference without freeing the memory. If the program leaks memory, it usually means that its memory consumption grows over time until the program runs out of memory and stops working. Here is the most basic example I could think of:
#include <iostream>
int main() {
double* n = nullptr;
for (int i = 0; i < 100000000; i++) {
n = new double(i);
}
}As you can see in the 4th line, we define a double* pointer called n and immediately initialize its value with nullptr. Later, in a loop, we create a new double with a value equal to the number of iterations. What is important here is that we do that without previously returning the memory to the OS. If we run this little experiment, the program finishes with a sad message:
... program finished with exit code 9Exit code 9 means something killed the process, usually the OS, due to exceeding memory limits. We ran out of allowed memory space, so the operating system killed our program.
The thing is, we can fix this problem with just one tiny line of code, just one:
#include <iostream>
int main() {
double* n = nullptr;
for (int i = 0; i < 100000000; i++) {
delete n; // new code
n = new double(i);
}
}Now, this runs without any problems.
Another way of causing a memory leak is to use an incorrect delete keyword. Consider an example:
void foo(char* dynamic_string) {
// do some operation on the pointer
delete[] dynamic_string;
}Here, we have a function foo that receives a reference to a char* variable called dynamic_string. The name suggests that this is a string, and implementing strings with a char[] was pretty common. We expect that this is an array. So we use the delete[]. But what about this case:
void foo(int* ref) {
// do some operation on the pointer
//how should we delete it?
//delete ref or delete[] ref
}
Unless we inspect the source code, we cannot know how this pointer was created. Let’s say we ended up using delete on a dynamically allocated array. What happens? An array pointer holds the address of the first element of an array, which means we would free only the first element, and all the other elements would leak.
Memory fragmentation
Memory fragmentation is best explained in a visual form, so here is our example memory block. Let’s say this is all we have for the program’s lifecycle. This buffer is 16 words wide:

Currently, it is empty. Naturally, as a program progresses, it loads some objects into memory.

Firstly, we allocated an orange object that’s 3 words wide, then 4 blue objects, each one word in size. Later, we allocated another orange object, and at the end, we had a green object, two words in length. Currently, we have used up 12 out of 16 available slots in the memory.
Our program continues to run, and at some point, we delete two blue objects:

This results in a situation where we have six words of free memory. Let’s assume that we want to allocate an object five words wide. How would we do it?
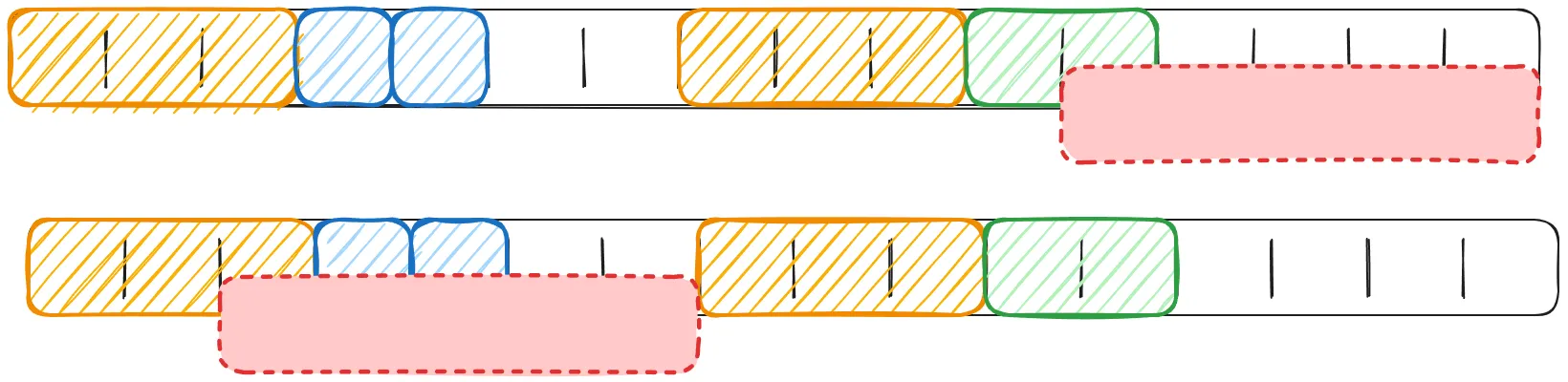
We cannot fit it at the end because we would overwrite the green object. It does not fit between blue and orange either. Even though in total we have enough memory (6 cells of free memory), we cannot squeeze this object into our address space because the memory is too fragmented. Memory fragmentation is an issue of memory management, where the program is unable to allocate memory without overwriting existing objects, even though in total there is enough memory.
So, what would happen in a situation like the drawings (which is not realistic)? Either the OS would succumb to our needs and allocate this object somewhere else, or the program would crash.
However, memory fragmentation only causes crashes in the direst of cases; typically, it makes the program run slow. Looking for a spot where our object can fit takes time, sometimes a lot. With many allocations and deallocations taking place this can become a real issue.
Smashing the stack for fun and profit
Interestingly, the C programming language has no default bounds checking, which means it is possible to load more memory into a memory buffer than it is supposed to fit. By manipulating memory on the stack, we could, for example, write a new return address of a function and run a terminal. I highly invite you to read an excellent article about this topic here.
Will humanity prevail?
Managing your memory might be problematic and can lead to catastrophic consequences. So what are we to do about it? One approach would be to create a system that does the work for us, that will take trash for us, a garbage collector.
Garbage collectors (GCs) are systems that follow all dynamically allocated objects and check whether they are used. A programming language that uses an advanced GC (like C#) will allocate objects until no memory is available. Then, it will ask the garbage collector to reclaim unused memory. This approach has two main caveats, firstly the process of collecting takes time. In games made with Unity, the activation of Garbage Collector can cause visible FPS drops. Another issue that was previously mentioned is memory fragmentation.
The GC usually fires when the memory is full. It analyses a graph that contains all the allocated objects and describes dependencies between them. If the GC finds an object that is unused by anything, the object gets deleted. Because this process is not strictly bound to the program’s execution, we might have a full memory before garbage collection, but after, we might have a memory full of holes. Memory fragmentation increases the time of any allocation and might cause another result in the Garbage Collection run.
C++ does not have a Garbage Collector, it is a language that gives its developers maximum control and focuses on performance. But this does not mean, that the problems of dynamic memory were not tackled in any way.
One idea of how we can help ourselves with memory management is RAII, Resource Acquisition Is Initialization. It is a mnemonic that describes a way of programming, and what it means is simple. Encapsulate resources into classes, where you acquire the resource in a constructor and release it in a destructor (more info). Like so:
class Foo {
private:
int* ptr;
public:
Foo() { // constructor
ptr = new int(5);
}
~Foo() { // destructor
delete ptr;
}
};Whenever an object of type Foo is created, we acquire the resource, and whenever it goes out of scope, we are sure that the resource will be deleted. Regardless of what happened during the execution, the program might have exited the scope normally or could have been forced to exit by an exception; the destructor will run.
This approach is great, but we have to remember to implement it. Humans are the biggest risk factor again. It might be that you forgot to delete that one pointer you allocated when you had to extend the class, or maybe you just used the wrong delete.
But with RAII in mind came another idea, something that works with the language and does not force programmers to delete all pointers every single time.
Smart pointers
This brings us to smart pointers, a curious approach to addressing issues that programmers have been experiencing for decades! Although impressive and extremely useful, they are sometimes confusing, so let’s dive deep.
Smart pointers are wrappers around raw pointers that embody a stack-based approach to managing heap-allocated memory. They help us by taking the responsibility of controlling an object’s lifetime. We have to decide which of them to use.
Technically, they are a form of garbage collection; they are barebone compared to more advanced systems in other languages.
In the history of C++ there has been 4 smart pointers
std::auto_ptrstd::unique_ptrstd::smart_ptrstd::weak_ptr
I’ve listed them chronologically, but let’s analyse them differently.
Unique Pointer
Introduced in C++11, the std::unique_ptr, just like a raw pointer, holds a reference to a variable but only to a dynamically allocated one. The word unique comes from its implementation, as it must be the sole owner of a resource; it employs so-called exclusive-ownership. When we create a unique pointer, it takes control over the raw pointer, and when we destroy it, it deletes the resource via an appropriate delete function. There are two main ways of creating a std::unique_ptr:
std::unique_ptr<int> unique_int(new int(5)); // through a raw pointer
//
std::unique_ptr<int> unique_int_2 = std::make_unique<int>(5); // through `std::make_unique`Although both are valid, the second is preferred. Now, let’s analyse the code a bit.
First, the type std::unique_ptr<int> is the first time we see these angled brackets < > used in the article. They are part of a C++ feature called templates. Templates are a way of metaprogramming where we can write code with type as a variable. Smart pointers use this feature extensively. As we learned in an earlier section, every pointer needs a type. When we write std::unique_ptr<int>, we specify that the pointer type is int.
Now to the second part, unique_int(new int(5)), I created a variable called unique_int and invoked a constructor of std::unique_ptr with reference to a newly created int with value 5.
std::make_unique<int>(5) is a way of creating a unique pointer without using the new keyword directly. The implementation of std::make_unique, of course, does use it underneath, but avoiding the new keyword is a safety practice that can be emplaced into the code standard of a given project.
To solve the problem of distinguishing between pointers to a variable and pointers to an array, the unique pointer API has in store for us two versions of the std::unique_ptr:
std::unique_ptr<T>- a unique pointer that takes a variable of typeTstd::unique_ptr<T[]>- a unique pointer that takes an array of elements and typeT
This means that the program knows which delete function to use when destroying the raw pointer, but it goes further than that. The single object version does not have the indexing [] operator, and for the array version, there are no dereferencing operators -> and . It is impossible to make a mistake between these two.
In C++, there is a concept of moving a variable (this is a feature of so-called move semantics; you can read more about it here). It means transferring a resource from one object to another without copying it.
In C++ there is a concept of moving a variable from one place to another. Moving results in one module of code yielding ownership over a resource and passing it to another module. Technically, all of the data from the original is copied to a new one, and the original gets deleted. std::unique_ptr is a move-only type. It cannot be copied, as such an operation would result in two unique pointers managing the same resource, which could mean destroying a pointer twice.
As I said before, smart pointers are wrappers around raw pointers and, in many cases, can be treated as such:
#include <iostream>
#include <memory>
int main() {
std::unique_ptr<int> up_int = std::make_unique<int>(5);
std::cout << *up_int; // dereferencing smart ptr
return 0;
}Usually, a std::unique_ptr is the same size as a raw pointer and performs the same operation, so you should not worry about performance. The situation changes slightly if one uses a custom deleter function. I will not dive into details, but imagine that you want to log each time a resource gets deleted. One can do it with a custom deleter. A custom deleter is a function object (an object that overrides call () operator) that will be stored with the unique pointer, thus increasing its size and decreasing its performance in exchange for custom behaviour. If you are interested, here are more resources about custom deleters.
Shared Pointer
std::shared_ptr builds on the idea of shared ownership. No shared pointer owns the resource it points to, all of the shared pointers manage the same resource they point to. This is achieved through reference counting, with each shared pointer created, the ref count increases and each deleted pointer decreases it.
The shared pointer is twice the size of a typical std::unique_ptr. Inside it, we find two pointers, one to a resource and another to something called a control block. The control block is an object that holds multiple things, one of which is the reference count.
How do these shared pointers share a control block? My initial thought was that there is a global mechanism that tracks raw pointers and their control blocks, but it is much simpler than that. The designers of this API assumed that there are four possibilities for creating a new std::shared_ptr:
// 1. From a raw pointer
Widget pw = new Widget;
std::shared_ptr<Widget> sp_w1(pw);
// 2. With make shared
std::shared_ptr<Widget> sp_w2 = std::make_shared<Widget>();
// 3. From a unique pointer
std::unique_ptr<Widget> up_w = std::make_unique<Widget>();
std::shared_ptr<Widget> sp_w3(std::move(up_w));
// 4. A copy
Widget* pw = new Widget;
std::shared_ptr<Widget> sp_w4(pw);
std::shared_ptr<Widget> sp_w5 = sp_w4;Let’s go through each of these and analyse what happens to the control block:
- If we create a shared pointer from a raw pointer, we know there is no control block because it should be a freshly created object.
std::make_sharedcreates a control block because it is the one that generates the resource. Here, we know that there is no control block.- Creating
std::shared_ptrfrom astd::unique_ptris allowed; we just have to usestd::movein order to move the pointer’s ownership. Remember that we cannot copy astd::unique_ptr! We know that the unique pointer is the exclusive owner of this resource, so we are sure no control block exists, and it must be created. - A shared pointer from another shared pointer, the control block is passed as a reference from
sp_w4tosp_w5.
So, when using a shared pointer, you must be mindful of how you create it. If a resource has two different control blocks, it could result in a situation where the pointer gets deleted twice, resulting in undefined behaviour. A good practice is to prefer std::make_shared over using new and passing a raw pointer to the constructor. Not only do we avoid making the mistake of creating two separate control blocks for the same resource, but we reduce the number of memory allocations from two to one(instead of creating a resource and then a control block, the memory is allocated for both).
It is important to note that shared pointers have a more significant cost than unique pointers. The shared pointer is twice the size of a typical std::uqniue_ptr. It also requires a control block, typically three words in length. The Control block’s implementation uses inheritance and virtual functions, which come with a small cost, and each time you create or destroy a pointer, you have to manipulate the reference count.
In most cases, this should be fine. Still, in tight environments, where each byte of memory is crucial, and every processor cycle is essential, you might want to consider something different than the comfort that a std::shared_ptr provides.
Weak Pointer
std::weak_ptr is a strange creature, but an interesting one. It has no dereferencing * or indexing [] operators, it cannot be created from a raw pointer. All this strangeness comes from the fact, that a weak pointer is not a standalone pointer, it is an extension of the std::shared_ptr.
Sometimes, having a shared pointer that does not change the reference count is what we need, which is precisely the job of a weak pointer. We can create a std::weak_ptr from a shared pointer or another weak pointer. It can be tested to check whether the raw pointer has been deleted. And if needed we can access the managed resource through a locking mechanism:
// Let's assume that in this scope there is a shared pointer available
// std::shared_ptr<Widget>s_ptr = std::make_shared<Widget>();
void foo() {
std::weak_ptr<Widget> w_ptr(s_ptr);
if (w_ptr.expired()) { // checking whether the pointer dangles
return;
}
std::shared_ptr<Widget> locked_weak_ptr = w_ptr.lock();
if (locked_weak_ptr) {
// Do something with this pointer
}
}The API for std::weak_ptr allows us to check whether the raw pointer has been (.expired()), or if we want to, we can create a std::shared_ptr by using the .lock() function.
Let’s analyse an example where a weak pointer can be helpful. Image a scenario in which you have three different objects, that have a relation like so:

Object A is owned by objects C and B. At some point in the development, we notice, that object A needs a reference to object B. How were we to do it? Consider using a std::shared_ptr:

If object A and object B were connected through a std::shared_ptr, we would have a so-called cyclic dependence. Object A would increase the reference count of B, and Object B would increase the ref count of A, making it impossible to destroy either.
A weak pointer is an excellent fix for such a case. Object A can hold a reference to B without increasing the reference count, making it possible to unload A whenever objects B and C have already been destroyed.

Auto Pointer
It is a relic of the past. First introduced in C++98, it tried to do the job of std::unique_ptr, but the language, at that time, was missing precise move semantics. With the introduction of C++11, it became deprecated.
But why did the C++ committee abandon it? The main issue was how std::auto_ptr transferred ownership over pointers. Technically, auto pointers have always had move semantics, but C++ performed moves indirectly through copying.
const auto_ptr<int> source(new int);
auto_ptr<int> target = source; // move from const source to targetWe can reveal the problems with this approach by putting some auto pointers into a data container and then applying some generic operation, like sorting:
vector<auto_ptr<int>> vec;
//
std::sort(vec.begin(), vec.end(), compare_obj());This code might result in undefined behaviour depending on how the sort method is implemented. Some implementations use a local variable to hold a copy of an element. If such a thing were to happen, we would transfer ownership over a pointer from an auto_ptr in our sequence to a local copy, which would be destroyed later.
To summarise, the issue with auto pointers comes down to performing a move operation with a copy operation. This operation is not harmful but does not work well with other parts of C++.
Because the std::auto_ptr was in a released version of C++, they could not just fix it; that would break backward compatibility. The committee decided to replace the auto pointer with the unique pointer.
The only reason to use the std::auto_ptr is when you must compile your code with a C++98 compiler. Otherwise, you can switch all auto pointers to unique pointers.
Summary
Smart pointers are great because they are part of the STL. They offer a solution to multiple problems that C++ developers have faced for a long time. Although they require some decision-making and thinking about the ownership characteristics of a resource, they prove to be extremely useful and flexible. Use smart pointers whenever possible.
I hope this paper has helped you understand what smart pointers are and why we should bother using them.
Bibliography
- https://learnxinyminutes.com/docs/c++/
- https://dictionary.cambridge.org/dictionary/english/variable
- https://cplusplus.com/doc/tutorial/variables/
- https://www.wikiwand.com/en/articles/Memory_address
- https://www.geeksforgeeks.org/memory-layout-of-c-program/
- https://www.wikiwand.com/en/articles/Virtual_address_space
- https://www.w3schools.com/cpp/cpp_pointers_dereference.asp
- https://learn.microsoft.com/en-us/cpp/cpp/data-type-ranges?view=msvc-170
- https://www.wikiwand.com/en/articles/Word_(computer_architecture)
- https://en.cppreference.com/w/cpp/language/raii
- https://learnopengl.com/Getting-started/Shaders
- https://docs.gl/gl3/glShaderSource
- https://github.com/llvm/llvm-project/blob/main/libcxx/src/new.cpp
- https://en.cppreference.com/w/cpp/types/NULL
- https://en.cppreference.com/w/cpp/language/nullptr
- https://www.wikiwand.com/en/articles/Dangling_pointer
- https://phrack.org/issues/49/14.html
- https://irkos.org/cpp/move/
- https://en.cppreference.com/w/cpp/memory/unique_ptr/unique_ptr