Preface
I want to research artificial intelligence in games, and I want to do it properly. This article provides an introduction to AI from a theoretical perspective and offers insights into AI applications in games. I hope this entry will be a starting point on which I can build later.
Throughout this article, we will focus on basic building blocks of artificial intelligence, what the common parts are between games and academia, and what the differences are. I will also point out the value of using the academic approach during the development.
To distinguish between the two, I will refer to the field of Artificial Intelligence as Academic AI and I will call the game development version Game AI.
Introduction
Right now artificial intelligence is the hottest topic in the tech world. When people hear AI their mind immediately goes to ChatGPT and other Large Language Models, but LLMs are not everything that there is to AI. I want you to forget briefly about models, machine learning or even image recognition. Let’s take a step back to basic definitions, methods and ideas and see how they connect to games.
Russell and Norvig define artificial intelligence as:
Formally, the field of Artificial Intelligence is about understanding intelligence and building intelligent entities that can compute how to act effectively and safely in novel situations. It’s a universal field that can be applied to any intellectual task.[1]
Even though AI in games comes from, and for the most part is, academic AI, I think it can be defined somewhat differently. The definition I would give for game AI would be something like this:
Game AI is about creating entities that appear intelligent and can efficiently compute how to act effectively in the game world.
So while AI tries to compute how to behave effectively in novel situations, in games, we try to create an illusion of that in a game world. This distinction makes the process of creating AI in games easier, but it doesn’t make it easy. Sometimes the easiest way of making an impression of being intelligent is to be intelligent.
When I say game AI, I mean the programs that are part of the experience, the non-player characters (NPCs). What I don’t have in mind are models like AlphaGo [2], which are created to be the best at a game.
Table of contents
Open Table of contents
Intelligent entity
In AI an intelligent entity is called an agent. An agent is anything that can perceive its environment through sensors and can act upon that environment through actuators. [1] Every agent has three parts: sensors, which it uses to perceive the world, internal logic that decides how to act, and actuators which allow it to act in the world. Let’s use an example to understand the concepts better. Imagine a game that fits this description:
A first-person stealth game set in a zombie post-apocalyptic world. The game world will be filled with zombie walkers that wander around a city looking for prey, and if they find something that's worth pursuing, they will run towards it with the intention of feeding.Sensors
A sensor of an agent is an object used to perceive the world. Sensors are distinct from senses, as sometimes the information from a sensor has to be interpreted to become a sense. There could also be multiple sensors of the same kind, like having multiple cameras in a car. The information inside a sensor is called a percept, and everything the agent has ever perceived is called percept history. [1]
A zombie should have at least three different sensors: two eyes, two ears and a nose. Giving them an ability to see, hear and smell.
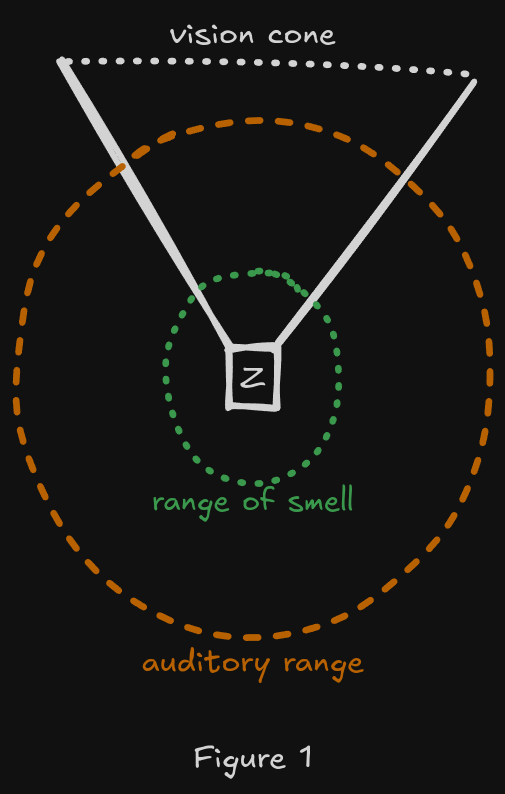
Actuators
Actuators are a way of interacting with the environment. How should zombies do it? By definition, zombies are not complicated creatures, but they do have a couple of ways of acting:
- Moving both slowly and quickly.
- Biting to kill victims.
- Feeding after the victim has been immobilized.
- Making noise to attract others or express themselves.
Though this seems like a few simple actions, they can be combined to create complex behaviors.
Internal Logic
Internal logic is the driver for the behavior, think of it as the brain of the agent. Its job is to interpret percepts from sensors and create actions that can be executed with actuators. This is the most important part of an agent, I am going to talk about it in more detail. However, let’s first discuss another important idea in AI.
Rationality
An important concept in the artificial intelligence field is rationality. A rational agent is an agent that is good at its job. How do we judge something like that?
An agent changes the state of its environment by performing actions. If the state of the environment goes from bad to good, then the agent is doing well. But good, bad or okay are human concepts unsuitable for a machine, that’s why researchers created something called the performance measure.
A performance measure is a value that we can calculate based on a sequence of states of an environment. It’s a quantified value of how good the agent is doing. For example, a performance measure for an agent that learns how to walk could give it a point for every step that it takes. More steps result in a higher score, indicating the agent did well! This is exactly what DeepMind did back in 2017.
A rational agent is defined as follows:
For each possible percept sequence, a rational agent should select an action that is expected to maximize its performance measure given the evidence provided by the percept sequence and whatever built-in knowledge the agent has.[1]
Notice that a rational agent is not perfect. It cannot make decisions with knowledge it doesn’t have. That’s why the definition says: for each possible percept sequence, and it also can’t see into the future, which is why it tries to maximize expected performance, not the actual performance measure.
Rationality also depends on the actions that are available to the agent. If an agent from DeepMind’s experiment had a car available to it, it wouldn’t be rational if it only tried running instead of driving.
Rationality is not something that we think specifically about when making games, and I think that there are two reasons for this.
Most of the time we are not trying to create truly intelligent agents, we are trying to create an illusion of intelligence. Players usually don’t have the means to evaluate the NPCs. Agent’s have to pass the implicit check of breaking the illusion of realsim.
Secondly, what we are trying to create is a fun experience. Like good, bad, or ok, fun is not something that we can measure and optimize for in an equation. We can ask players for feedback whether the experience was fun or not, but we cannot measure it beforehand or during gameplay. I think that in games, the performance measure is the feedback from players, but until that feedback is given, the performance measure is guessed by the developers of the game.
Environment
The environment is an agent’s world, and it’s as important as the performance measure the agent uses. Different methods can be used to create an agent’s internal logic depending on the environment in which it exists. To define an environment we can ask questions like: Where an agent will be? What will be there?, etc.
The answers might differ drastically between different agents. Take our zombie as an example, its environment is a city, with streets and buildings to navigate, along with other zombies and some non-zombified creatures. On the other hand a chess agent would have a completely different environment: an 8 by 8 grid with chess pieces.
The set of all possible environments is extremely large, yet they all share characteristics that we can use to describe them:
- Fully Observable vs Partially Observable - whether agent’s sensors have complete access to the state of an environment at each point in time.
- Single Agent vs Multi Agent - are there any other agents, and what’s the relation between them? Are they working against each other (competitive environment) or with each other (cooperative environment)
- Deterministic vs Nondeterministic - is the next state of an environment completely determined by the current state and agent’s action? If so, then the environment is deterministic.
- Episodic vs Sequential - an episodic environment can be split into independent parts to which the agent has to react. Imagine a machine that looks for defects in an assembly line. Sequential environments have a cause and effect feature; past decisions affect consecutive states.
- Static vs Dynamic - static environments don’t change when an agent is in the process of making a decision. A dynamic environment can change, and don’t wait for agent’s input.
- Discrete vs Continuous - does an environment change in a step-like manner or does it change smoothly? The real world is a continuous environment, it’s difficult to pick out a specific “moment” in time. While on the other hand, chess is a discrete environment, it has finite number of different states that can be easily defined.
- Known vs Unknown - this is more about the agent not about an environment, but it comes down to: does the agent know the rules of the environment? Does it know what consequences its action will have? Does it know the “rules of physics”?
The worst possible case is: partially observable, multi-agent, nondeterministic, sequential, dynamic, continuous and unknown. Yet this case is more challenging than some of the hardest problems in the real world, because for most cases we know the rules of physics. An environment of a chess agent would be fully observable, multi agent, deterministic, sequential, static, discrete and known.[1]
One of the most important differences between video games and the real world is that, as creators of a game, we design the environment. We don’t have to struggle with some of the complex problems because we have the power to simplify. We can make the environment fully observable, deterministic, and known, which is a significant advantage over the physical world.
That is not to say that games don’t have complex behaviors. The concept of a player makes the environment multi agent, but there are games that have dozens or even hundreds of agents working at the same time (e.g. RTS games). All games are sequential, and the vast majority have a dynamic environment, but there are some successful games with static environments (e.g. Into the Breach). Every game that doesn’t have turns has a continuous environment. However, I can’t stress this enough, we know the rules, and we can change them at will.
What does the agent do?

How do we implement an agent? Let’s start by analyzing an example. From the description of our zombie we can extract a couple of behaviors:
[...] The game world will be filled with zombie walkers that wander around a city looking for prey, and if they find something that's worth pursuing they will run towards it with an intention of feeding.- If there is no food -> wanders around
- If it sees food -> Runs for it
- If it sees food AND it is close enough for eating -> eats it
Here we have a couple of behavior rules, which are mappings of percept sequences to an action that the agent should take.
Regardless of their type, all agents fundamentally do the same thing. At any given time an agent selects an action, based on its percept history observed to that point in time. Mathematically speaking we can say that the agent behavior is described by an agent function, that maps any given percept history to an action. [1]
(percept sequence) -> actionThe implementation of the agent function is an agent program, it is the mapping between percept history and actions. But, the program has to run on something: a PC, a robot, or a game object with a model attached to it; it need some sort of compute device with sensors and actuators. This is called the agent architecture, and its job is to pass percepts to the program, run the program, and execute the actions from the program.
An algebraic function can be thought of as a table that maps input to the output:

So can be an agent function:
| Percept History | Action |
|---|---|
| … | … |
Figure 5. Percept-action lookup table
How big the lookup table is going to be depends on the environment and an agent’s lifetime.
Let be the set of all possible percepts and let be the lifetime of the agent (the total number of percepts it will receive). The table will contain entries. For chess, a game with a relatively small environment and simple rules, the lookup table would have at least entries. [1] In comparison, the number of atoms in the observable universe is . It is physically impossible to store and design a lookup table for a game of chess.
This brings us to an important conclusion: the job of the field of artificial intelligence is to find out how to create rational programs that are smaller than a lookup table. Here, we can intuitively understand the phrase: “intelligence is compression”.
Implementing the agent
There are more practical ways to implement an agent program than a lookup table. In video games, the most common approaches are Finite State Machines and Behavior Trees. But there are also other ways: behavior graphs, utility-based approaches, GOAP, scripting, etc. Too many to fit in this article, but in general, agent programs can be categorised into four basic groups:
- Simple reflex agents.
- Model-based reflex agents.
- Goal-based agents.
- Utility-based agents.
Simple reflex agents
Simple reflex agents are the most basic type of agent. They base their decision only on the current perception, ignoring anything that happened in the past. Our zombie is an excellent example of this type of agent
function ZombieProgram(Percept) -> Action
if IsFoodInRange(percept) then
return actions.Eat
if CanSeeFoodSource(percept) then
return actions.Run
return actions.WanderAround;Figure 6. Implementation of a simple reflex zombie agent
The fact that we are ignoring what happened in the past (the percept history) drastically reduces the number of possible states. These types of agents are very simple, and I say this as a positive. However, their correctness is questionable. They work properly if and only if a good decision can be made based on a single percept and the environment is fully observable, which is rarely the case.
Model-based reflex agents
Imagine a simple reflex-based zombie, while wandering around a city, it sees a human at a distance. According to Figure 5, it will make a run for it, growling and screaming along the way. This makes the human survivor notice our agent, and they run away. What happens now? By Figure 5, the agent should get back to wandering around. But that’s silly, changes of behavior as soon as the percept vanishes break the illusion of intelligence, even zombies aren’t that simple.
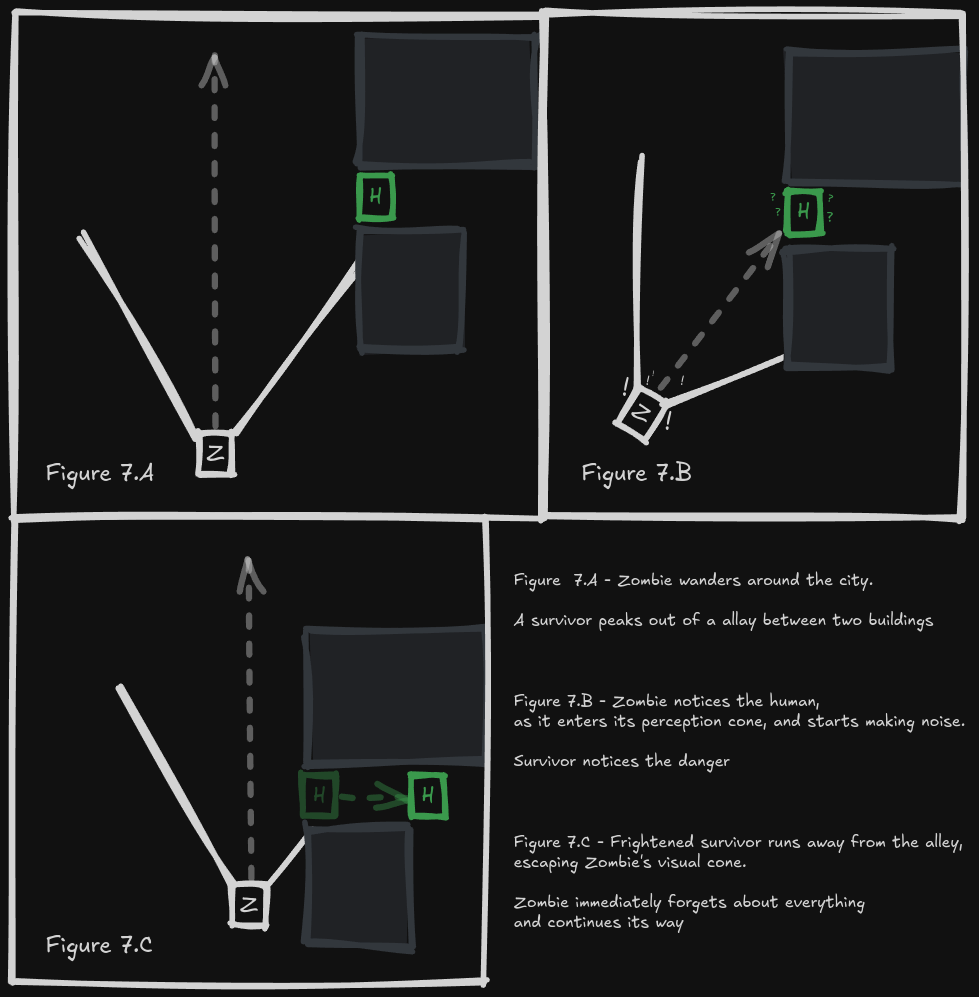
Our agent should remember that it saw food just a moment back, and it should include this saved information in its decision-making process. That’s exactly what a model-based reflex agent does. It keeps track of the world by maintaining some sort of internal state. This state depends on the percept history and, in turn, allows the agent to behave in a more reasonable manner.
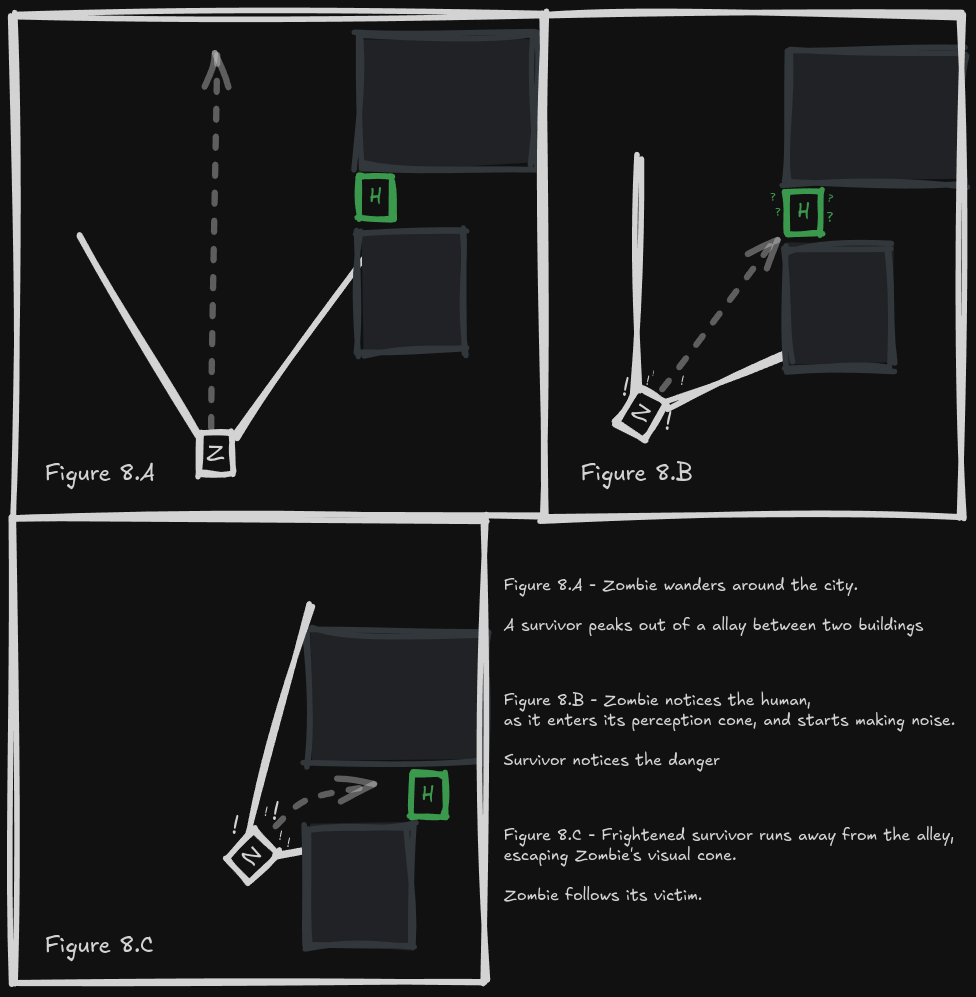
In our case, the zombie could remember the positions of potential victims it saw. Depending on how much time had passed since it spotted them, it could investigate the place or just give up. There’s no point in checking a spot it saw a rabbit two days ago - unless the game requires it. Or the zombie does.
Finite State Machines
I mentioned previously that Finite State Machines are the most common technique for creating AI in games. They are a tool that helps designers and developers think about AI behavior through states and transitions. Here’s an example of a finite state machine for our zombie:
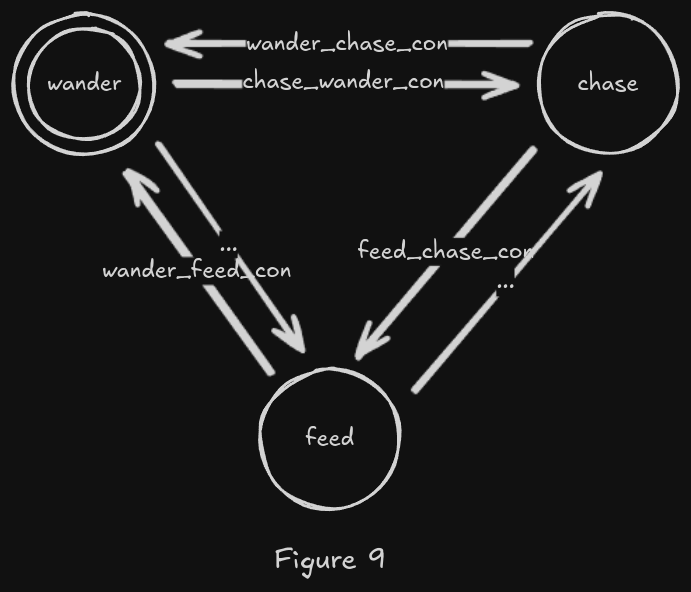
In short, a finite state machine (FSM) has a current state (marked with a double circle in the diagram) and transitions (arrows between the states). Each time an Agent updates its behavior, it:
- first checks if any of its current state’s transitions are valid. If so, the current state is changed. If no, then the current state is kept. For example, the transition
chase_wander_confrom thewanderstate could check if the agent sees anything worth chasing. - Secondly, it updates the behavior associated with the current state.
Finite State Machines and Behavior Trees are both methods that abstract the complexity of a rule-based approach. They are great for visualising, creating and thinking about an agent’s behavior, but they still operate on if-else statements.
Yet, simplicity can be a good thing for a tool; it’s difficult to get an estimate of how many games were created with this approach, but they are considered among the most popular. When combined with other approaches, for example, for pathfinding, developers can create memorable experiences.
Goal-based agents
So far, the agent program was concerned with checking and reacting to certain conditions that depended either on the current percept or on the percept history. Yet knowing how to react to the situation might not be enough, even if an agent is internally tracking the state of the world. In some cases, the agent has to achieve a certain goal: change the state of the environment to satisfy specific conditions.
Zombies usually don’t have a brain, and complex thinking is out of their league, but imagine a messenger trying to get to the capital of its country with an important message that the borders are being attacked.
Which way should he go? Writing a rational condition-based agent would be near impossible. But there are two approaches we could take: searching and planning, which are both sub-fields of Academic AI.
Searching is more of a brute-force approach. By looking through all the possible states and actions that create changes in the state, we can find a list of actions that would result in meeting the goal. An example of a searching agent would be Monte Carlo Tree Search, where it searches through all possible actions, foreseeing what consequences it would have. A* is another example, since we search a graph for a path from a start node to a destination.
Planning is a bit more advanced. It creates a sequence of actions, a plan, from a set of available actions; the main difference is that it doesn’t explore all of the states. The most popular planning technique is called GOAP, a goal-oriented action planner. Introduced by Jeff Orkin in F.E.A.R [4]. In this game, NPCs plan manoeuvres in order to remove threats, i.e. the player [3].
The great thing about goal approaches is that they are more flexible than rule-based systems. F.E.A.R. was praised for its AI, and there were comments that the AI is innovative. NPCs not only use all the tools that are available to them in a smart way, but they also communicate with each other by shouting what they plan to do.
The trade-off between the goal and rule-based approaches is: the implementation complexity and the direct control over the agent’s action versus the intelligence and autonomy of the agent. It’s more difficult to make and a good planner, but when it works, it might be much better than what we made with an FSM or a BT.
Utility-based agents
An agent with a goal is trying to influence its environment in a way that satisfies the goal. Regardless of how the agent performed its actions, the agent is “happy” when it’s done.
However, we as humans often care about the how, we consider the cost and the performance. Goal-oriented agents are unable to work with multiple goals at once; they have to chain them together. In such scenarios, the utility-based agent can provide a better solution.
A utility-based agent works by using a so-called utility function. This function assigns a score to any given sequence of environment states [1]. Allowing it to calculate how “happy” it is with different states. This idea connects to the concept of rationality and how academic AI evaluates agents. A utility function is an internalised version of the performance measure. If the internal function is aligned with the performance metric, an agent that maximises its utility score is rational.
A great example of this technique is The Sims [5]:
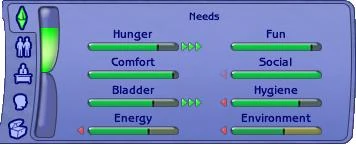
If you are unfamiliar with The Sims, it is a series of games in which you simulate real life. You can control avatars, or Sims, and go on a journey through life with these characters. They need to take care of their basic needs like food or hygiene, but they also have to take care of their education, professional life or family life. In the game, player can control any Sim by themselves, but if left to tend for themselves, they are going to minimise problems with their needs. Then we could say that the overall goal for a Sim Agent Program would be to take care of a sim. Depending on their state, they would choose different actions.
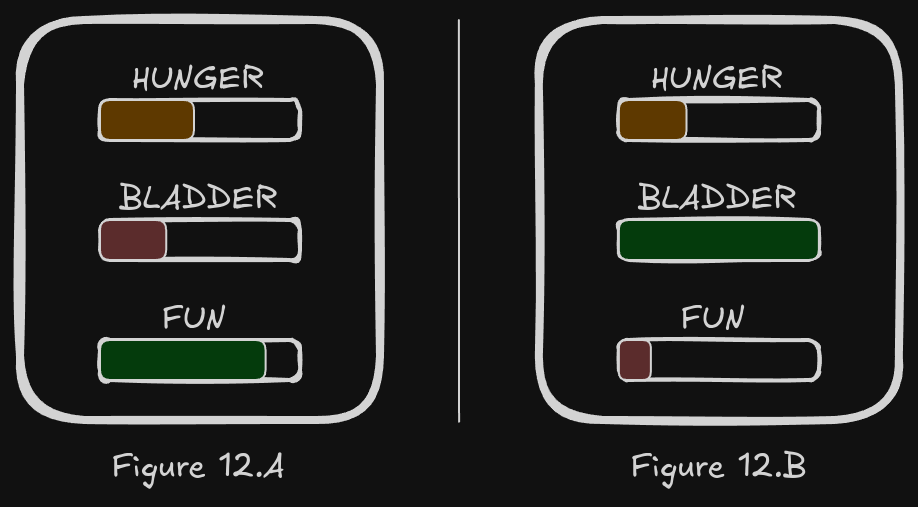
The needs have different levels and also different priorities. Have a look at Figure 12.A. A generic Sim would run to the bathroom, then to the fridge, and then it would proceed to do something that’s fun. That’s a very natural progression; the lowest needs are taken care of first. But Figure 12.B shows something different; the plan here would look like this: first eat, then play. Even though fun has a much lower value than hunger, the utility function that the agent is using prioritises hunger.
It is important to mention that the utility approach can be helpful in non-deterministic environments. Instead of maximising the utility score, an agent can use the expected utility. For any action , the expected utility is equal:
Expected Utility of an action a is equal to the utility of that action multiplied by the probability of that action happening.
By incorporating the probability of success into a factor that we are trying to maximise, the agent can make decisions in environments that are partially observable and nondeterministic. Under the condition that the probability is known when making the decision.
Utility is the most flexible approach out of all, and actually mimics how we think about the design of intelligent agents. But it is no silver bullet; it requires a lot of work, as each action or state needs a score function. These functions have to be thought of, fine-tuned, and taken care of.
Academic theory and games
You might be tempted to think that we should always be using the most advanced solutions in every game since they give us the most interesting gameplay and the most flexibility. But I don’t think this is right. Each of these approaches has its pros and cons, and we should weigh the decision based on the game we are making. Not every plane needs a jet engine, and not every game needs a complicated AI. Sometimes it’s better to use a tool that gets the job done quickly, and you know how it works.
I also think there is real value in using the academic definition of an agent when designing an NPC in a game. When we define what an agent is, we can ask questions to make this definition specific to a particular game we are working on: what sensor should the agent have? What actuators should it have? What are the most important percept-action pairs we want to implement? I believe that asking these questions helps with communication between a designer and a programmer. It wasn’t uncommon for me to get a convoluted design document of an NPC. Every time that happened, I felt like the designer was unsure of what they wanted. Now I would ask these questions and hope to iron out the basics.
Bibliography
- Russell, S. & Norvig, P. (2021). Artificial Intelligence, Global Edition. (4th ed.). Pearson Education. https://elibrary.pearson.de/book/99.150005/9781292401171
- Silver, D., Huang, A., Maddison, C. et al. Mastering the game of Go with deep neural networks and tree search. Nature 529, 484–489 (2016). https://doi.org/10.1038/nature16961
- Orkin, J. (2008). Applying Goal-Oriented Action Planning to Games.
- Monolith Productions, F.E.A.R., Windows, Vivendi Universal Games, 2005.
- Maxis. The Sims 2. Redwood City, CA: Electronic Arts, 2004.